Interrupts and Exceptions
It would be awesome if you first read this
Some event triggers are synchronous, meaning that the currently executing instruction is the one that caused the event trigger... whether is was done deliberately or randomly we don't care.
Other event triggers are asynchronous, meaning that the event trigger was not caused by the currently executing instruction. It was caused by something other tan the currently executing instruction
Here are the asynchronous triggers :
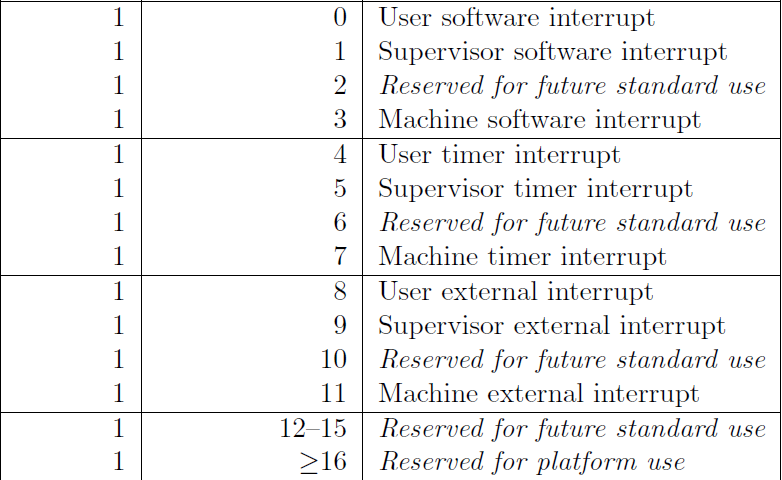
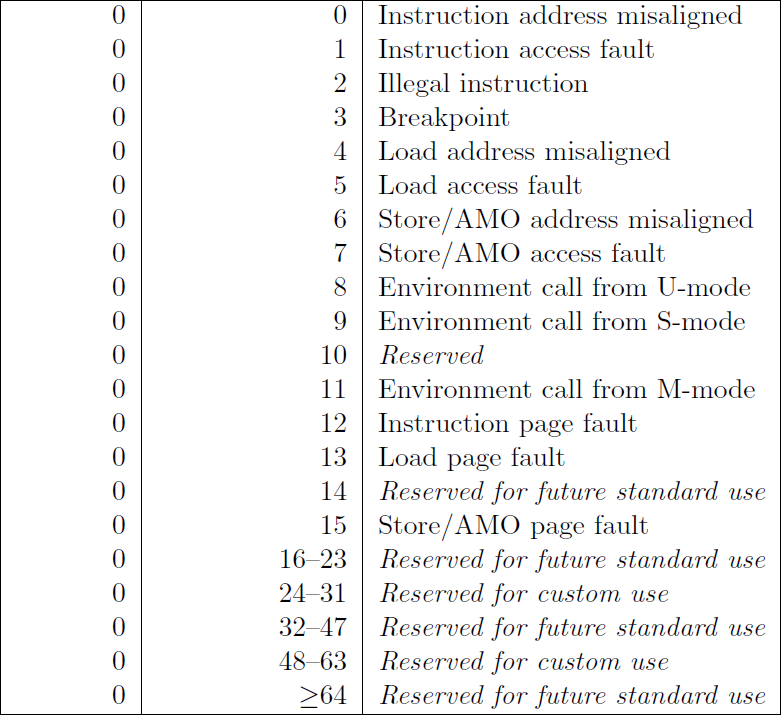
Here are the synchronous triggers :
RISC-V Interrupt System
The riscv system allows you to handle traps in all the CPU modes : usermode, supervisor mode and machine mode.
But our system will handle all OS interrupts and traps in machine mode..
When an interrupt happens, the cpu :
- updates the mcause register
- updates the mepc register
- updates mtval register
- saves the context of the current program . We save this context in a trap frame. We store the trap frame in a mscratch register.
- calls the interrupt handling function.
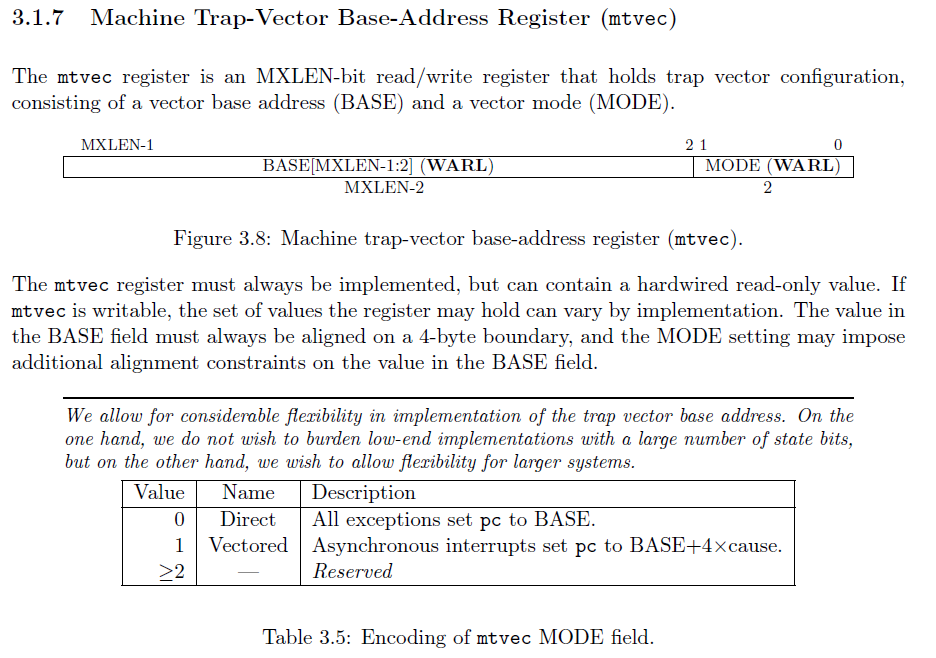
The address of the interrupt handling function is stored in the mtvec register (Machine Trap Vector). A vector is a fancy word for saying "pointer to a function"
We will use Direct mode of handling interrupts, we wil not use the vectored approach.
Below is the the structure of the mtvec register :
THe mcause register store information about :
- The type of interrupt (whether it is synchronous or asynchronous) 0 == Synchronous, 1 == Asynchronous
- The code specifying the cause of interrupt eg code 12 == instruction page fault
we will handle rhe flow of interrupt handling using the following files :
- boot.s
- trap.s
- trap.rs
boot.s
boot.s contains the assembly code that
- Initializes CPU registers and makes the mecp register point to the entry point of the kernel code ie kmain. so that if we call mret... the kernel code starts executing.
- It makes the mtvec point to the asm_trap_vector function. The asm_trap_vector has been defined in the trap.s file
trap.s
This file defines the assembly code that does the folowing :
- Saving the context of the interrupted process.
- Set up the suitable context for the m_trap function.
- Call the entry point of the Rust code that defines how each interrupt is handled.
- Restore the context of the interrupted process.
- Return control to the interrupted process.
trap.rs
This file defines the Rust functions and structures to handle interrupts
- defines the entry point function
- defines the structure of the interrupts
- defines the error handler for each interrupt (adjust the program counter appropriately)
We are going to borrow the RISCV macro, no-one has time to learn that stuff
The Trap Frame
#![allow(unused)] fn main() { #[repr(C)] #[derive(Clone, Copy)] pub struct TrapFrame { pub regs: [usize; 32], // 0 - 255 pub fregs: [usize; 32], // 256 - 511 pub satp: usize, // 512 - 519 pub trap_stack: *mut u8, // 520 pub hartid: usize, // 528 } }
We store the SATP because it might change when a context switch happens. Maybe the SATP will reference different Root table for another RAM, Maybe the ASID will change, The ASID tells us which process was executing (process ID) [unsure]
Rust function to handle Interrupts
inputs : 1. cause : helps us determine the type and code of the interrupt 2. epc : helps us determine the latest value of the program counter 3. tval : some error handling functions need the matval eg in a page fault, the mtval registe contains the address of the faulty page 4.
Output : the program counter to the next instruction after the error handler has done its thing
Steps : 1. Check if the interrupt is synchronous or asynchronous. We divide this way for modularities sake. Also it is a standard convention. - If the interrupt is synchromous, go to step 2 - If the interrupt is asynchromous, go to step 6 2. Extract the cause code from the mcause 3. Make the return address point to the mepc... since this was the latest program counter 4. use a switch to call specific error handling functions based on table x 5. return the updated program counter 6. Extract the cause code from the mcause 7. Make the return address point to the mepc... since this was the latest program counter 8. use a switch to call specific error handling functions based on table y 9. return the updated program counter
Table x
Table y