Filesystem
References :
Theory
What is a file?
A file is a named collection of static data.
Data can be a byte, a couple of bytes or gigabytes.
The data collection needs to be static so as to store data persistently. So in this case, files can be redefined as : A named data collection in a persistent storage device.
File Types
There are different types of files. Types emmerge due to either "the file format" or "the file purpose".
For example an elf file has a different format to a .exe file... but they serve the same purpose.
Another Example : An elf file that has code that services other programs gets defined as a system file - Its purpose is to provide low-level support. On the other hand, an elf file might contain code that runs as a user program. Such a file is not regarded as a system file but as a user file. Point is : "You can define file types because of their purposes. Pretty subjective, right?. This is not a discrete way of classifying files.
A data file has the same format as a system file... but they serve different purposes
More File Types include :
- Regular Data Files : These are files that contain user-level information. It can contain Binary data or ASCII data.
- Directory Files : These are files that describe the structure of the file system
Before we go further, let's get some buzzwords out of the way :
- Block device
A block is a kind of storage device that allows data to be read and written to it in fixed sizes called blocks. A block is a large group of bytes. From this, it is clear that a block storage device consists of many many bytes. For example a HDD device or SSD device.
A Character device
A character device is also a storage device that only allows data to be read and written to it character-wise... or rather in a byte-wise way. You cannot extract data from it in chunks or blocks
Block devices are suitable in situations where we need performance. This is because Character devices force the CPU to do more I/O operations. I/O operations are expensive as hell. We always need performance
Character devices are suitable when we need data in a stream-wise fashion... a continuous fashion. Eg data from a keyboard or a mouse. Keyboards and Mice are character devices. Character devices are preferrable when you need to extract data in a real-time situation... you need data coming in a continuous stream. Like a keyboard or mouse. Can you imagine a mouse that is not 'real-time'?
A disk Partition
A disk is a fancy name for a hardisk ... a hardisk is a type of a block device.
A partition scheme is a specification of how to logically seperate bytes in a hard disk into seperate sections called partitions.
We have many partitioning specifications eg MBR, UEFI, GPT LVM. These specifications specify things like how the metadata for each partition gets stored and which kind of information gets stored as metadata.
If you use a partitioning software to partition your disk, your disk will typically have 3 parts...
- The partial_boot code : The partial boot code will help the firmware locate the bootloader that may be found in one of the partitions
- The partition table : This table contains metadata about the partitions.
- The actual Partitions
The Partition Table
The Partition table contains metadata about the partitions. It typically contains info such as :
- The file systems found in each partition
- The status flags of each partition eg : Bootable flag, writable flag
- The size of each partition
- The memory boundaries of each partition (start address and end addresses)
- The type of each partition (primary? swap? extended? logical? )
A File system
A file system is a software definition of how the bytes in a block device are organized. To be more specific a file system is a software definition of how the bytes in a partition are organized.
We have many file systems in existence...each with their own usecase and trade-offs. For example : NTFS, ExFAT, EXT4, BTRFS and Minix 3 File system.
We will focus on the Minix 3 file system... but with tweaks. Minix 3 is simple and easy to implement. It does not have many advanced features that are found in file systems like NTFS and BTRFS. It is still, no surprises.
Minix 3 File System (a Variation)
The minix 3 Filesystem organizes the bytes within a partition as follows :
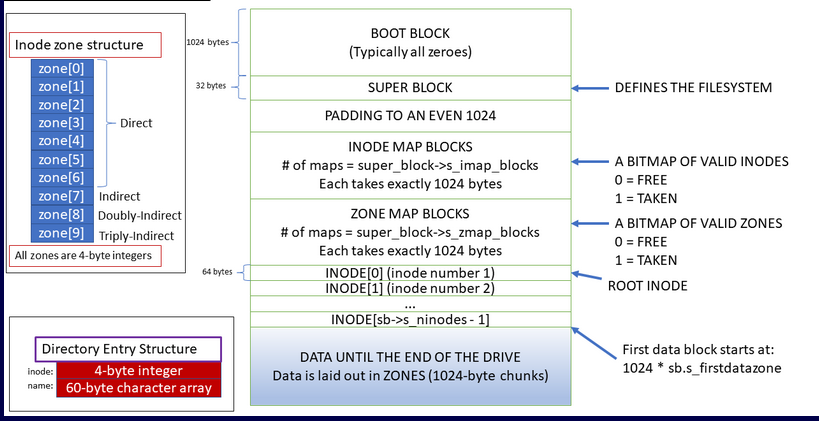
A block
A Block is a group of bytes. Like in minix 3, a block typically means 1024 contiguous bytes. But this is not always the case. For example, the superblock is only 32 contiguous bytes. Let's just say, it is convetional to read data as 1024-byte chunks... but you can figure out how to read in other sizes if you tweak things in the file system.
A zone
A Zone is a group of blocks. Like in Minix 3, a zone usually contains 4 contiguous blocks. Meaning a zone is typically (4 x 1024) bytes.
An Inode(Index Node)
An Inode is a descriptor for a single file. It contains information such as : the file type, the file size, the addresses of the blocks that the file has used.
A bitmap
A bitmap is an array of bits. Where each bit symbolyses the status of an inode or a zone. To keep track of what inodes and zones (blocks) have already been allocated, the Minix 3 file system uses a bitmap
The Boot block
This section might contain boot code for an operating system. If there is no operating system...this section is filled with zeros. The bootblock is 1024 bytes long. Sometimes the 1024 byte is not enough to store the entire bootloader code... in such a case, part of the boot code will get stored in the Data zone.
The SuperBlock
The Superblock is 32 bytes long.
The Superblock contains metadata about the entire Filesystem. Here is a struct showing the data contained in a superblock :
#![allow(unused)] fn main() { #[repr(C)] pub struct SuperBlock { pub ninodes: u32, // the total number of index nodes pub pad0: u16, pub imap_blocks: u16, // pub zmap_blocks: u16, pub first_data_zone: u16, pub log_zone_size: u16, pub pad1: u16, pub max_size: u32, pub zones: u32, pub magic_number: u16, // identifies the file system type (Minix == 0x4d5a) pub pad2: u16, pub block_size: u16, pub disk_version: u8, } }
Do not mind the terms like inodes and zmaps, we will cover those in a bit.
The superblock does not change once the partition gets mounted. This is because the superblock contains static information such as "the number of inodes" which will only change when you resize the disk.
Our file system code only needs to read from this Superblock structure. Recall that we can find this structure after the boot block. The default block size of the Minix 3 file system is 1,024 bytes, which is why we can ask the block driver to get us the super block using the following.
#![allow(unused)] fn main() { // descriptor, buffer, size, offset // synchronous_read ... it's synchronous because we suspend the calling code until the read operation is done. // If it were an asynchronous read... the calling code would have continued doing other things as it waits for the I/O operation to end. syc_read(desc, buffer.get_mut(), 512, 1024); }
The super block itself is only about 32 bytes; however, recall that the block driver must receive requests in sectors which is a group of 512 bytes. Yes, we waste quite a bit of memory reading the super block, but due to I/O constraints, we have to. This is why I use a buffer in most of my code. We can point the structure to just the top portion of the memory. If the fields are aligned correctly, we can read the superblock by simply referencing the Rust structure. This is why you see #[repr(C)] to change Rust's structure to a C-style structure.
The Superblock is 32 bytes but our block read function reads 512 bytes at once. So we will just read the 512 bytes and store them in a buffer... from there we can just disect it using offsets of u8
The Padding to even out a block to 1024 bytes
[undone] : document the other parts of the disk partition.
THe Z map and imap
The Z map is a bunch of 1-bit arrays. Each bit represents an existing zone. 1 means the zone is taken and 0 means the zone is free.
The Imap is a bunch of 1-bit arrays. Each bit represents an existing inode. 1 means the zone is taken and 0 means the zone is free.
The Inodes Structure
The Inode contains the following fields : i_mode: This field specifies the file type and permission modes. It indicates whether the inode represents a regular file, directory, symbolic link, etc., along with the read, write, and execute permissions for the owner, group, and others.
**i_uid:** This field stores the user ID of the file's owner.
**i_size:** This field indicates the size of the file in bytes.
**i_time:** This field stores the last access, modification, and status change timestamps of the inode.
**i_gid:** This field stores the group ID of the file's group.
**i_nlinks:** The number of hard links to the inode. This is used to track how many directory entries point to the same inode.
**i_zone:** This is an array of zone numbers that point to the data blocks of the file. In MINIX, data is stored in zones, which are similar to blocks in other file systems.
**i_indir_zone:** This points to an indirect block. This indirect block can be used to store additional zone numbers if the file size exceeds the direct zone capacity.
**i_dbl_indir_zone:** This points to a doubly indirect block, which in turn can point to multiple indirect blocks. This is used when the file size is even larger.
**i_tpl_indir_zone:** This points to a triply indirect block, which can be used to handle extremely large file sizes.
**i_flags:** This field stores various flags related to the inode, such as whether it's a directory, whether it's marked as deleted, etc.
Now the inode can be a DIRECTORY file or REGULAR file
The zone pointers of a directory node point to zones that contain Directory structures instead of normal data.
A directory structure takes the following format :
#![allow(unused)] fn main() { #[repr(C)] pub struct DirEntry { pub inode: u32, pub name: [u8; 60], // Stores the name of the File associated with the innode } }
Implementation
To implement the File system in the project, we have to do the following tasks :
- Make the hdd virtual file to have the MINIX 3 file system.
- Port a minix 3 File system driver into the kernel. We are not going to write our own driver, but we will after exams or smth (time issue)
1. Making the Hard-disk to have a MINIX 3 file system
Linux comes with a command line tool called Losetup (Loop devices setup).
This tool helps you set up and control loop devices
A loop device is a regular file that has been abstracted as a block device. The file's content is still a stream of characters but the losetup makes interaction with it to be similar as to how you would interact with a real block device.
This tool can be important when testing drivers for block devices.
In our case, we make the ./hdd.dsk file to be a loop device.
To find out more about the losetup, check out the manual pages by running the terminal command :
man losetup
You can also read this Straight tutorial.
Here are some of the common commands :
losetup --list // Display information about active loop devices.
losetup --all: // Display information about all loop devices.
To set up the Hard-Disk, read through this.
[undone] : Finish Documenting this part
2. Port a minix 3 File system driver into the kernel
[undone] : Finish Documenting this part
CAN I JUST USE THE PREDEFINED MINIX FILESYSteM?????!!!! [design] [trade-off]
Random thoughts
If you make a function a process, it can be executed independently if it is pure non_dependent code.
Our file block driver initially did synchronous reads. Synchronous reads bad for performance.
We need to mak our file reads asynchronous. Asynchronous reads are good for performance.
We can make our file reading asynchronous by turning the file reading operation into a kernel process... instead of a procedural function. This kernel process will only be ready to get executed if we receive an interrupt from the block device.(the block device sends interrupts to signal that it has finished a read operation).